In my last post, I presented a fast and easy way to add binary clauses to the clause database of SAT solvers, and I conjectured that since the algorithm was so simple, there must be something wrong with it. I was, in fact, right. I ran a cluster experiment, and it turned out that adding all those binary clauses was slowing down the solving.
My first reaction was of course: how on Earth? Binary clauses are “good”: both MiniSat and Glucose try to amass these clauses as much as possible. So what can possibly be wrong? Well, redundant information, for a start. Let’s assume that we know that
A leads to B B leads to C
If I now tell you that
A leads to C
it wouldn’t really help you. However, the algorithm I presented last time didn’t address this issue. It simply added a good number (though, luckily, not all possible) binary clauses that were totally redundant.
The trick of adding binary clauses is, then, to add as little as possible to achieve maximal graph connectivity. And, while we are at it, we can of course remove all redundant information like the one I presented above. Neither of these two are easy. I use the Monte-Carlo method to approximate the degree of vertexes for the first algorithm, and then sort vertexes according to their degrees when adding binary clauses. The second algorithm just needs a bit of imagination and a will to draw graphs on a piece of paper.
So, there is a point in being dumb: without the hands-on knowledge how binary clauses negatively affect problem solving, I would never have thought of developing such algorithms. The final algorithms take ~3-4 seconds to complete, add (fairly close to) the minimum number of clauses, remove all redundant clauses, and work like a charm.
There is only one thing to understand now: why does Armin Biere add hundreds of thousands of binary clauses? I seem to be able to achieve the same effect in a couple of thousand… Again, I must be dumb, and he must be doing something right. I am lost, again :(
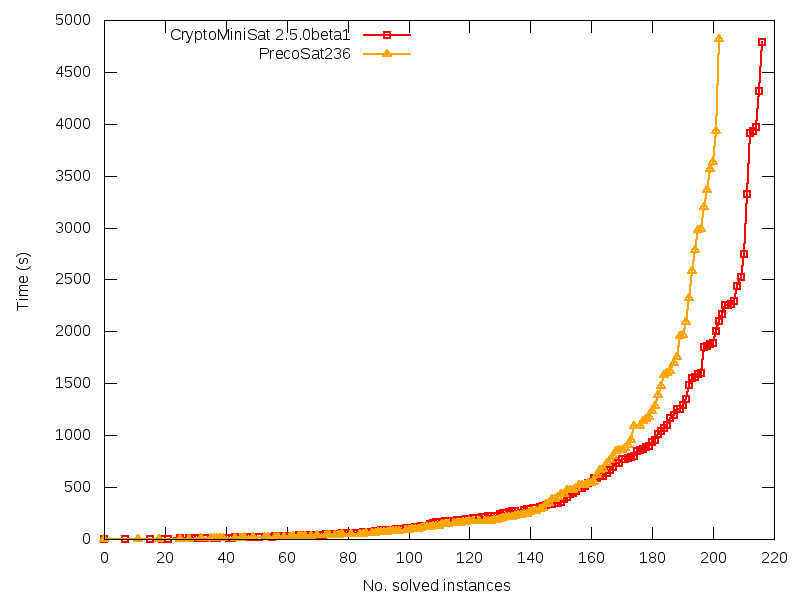
EDITED TO ADD: You might enjoy this plot of PrecoSat236 vs. CryptoMiniSat 2.5.0beta1 on the SAT Competition instances of 2009.
{kind=link}