CryptoMiniSat 3.0 has been released. I could talk about how it’s got a dynamic, web-based statistics interface, how it has more than 80 options, how it uses no glues for clause-cleaning and all the other goodies, but unfortunately these don’t much matter if the speed is not up to par. So, here is the result for the 2009 SAT Competition problems on a 1000s timeout with two competing solvers, lingeling and glucose:
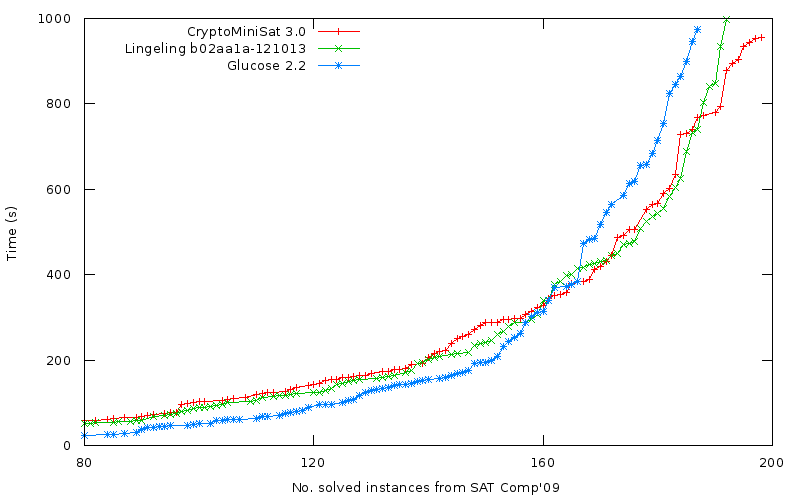
This of course does not mean that CryptoMiniSat is faster than the other solvers in general. In fact it is slower on a number of instances. What it means is that in general it’s OK and that’s good enough for the moment. It would be awesome to run the above experiment (or a similar one) with a longer timeout. Unfortunately, I don’t have a cluster to do that. However, if you have access to one, and would be willing to help with running the 3 solvers on a larger timeout, please do, I will post the updated graph here.
Update Norbert Manthey kindly ran all the above solvers on the TU Dresden cluster, thanks! He also kindly included one more solver, Riss 3g. The cluster was an AMD Bulldozer architecture with 2cores/solver with an extreme, 7200s timeout. The resulting graph is here:
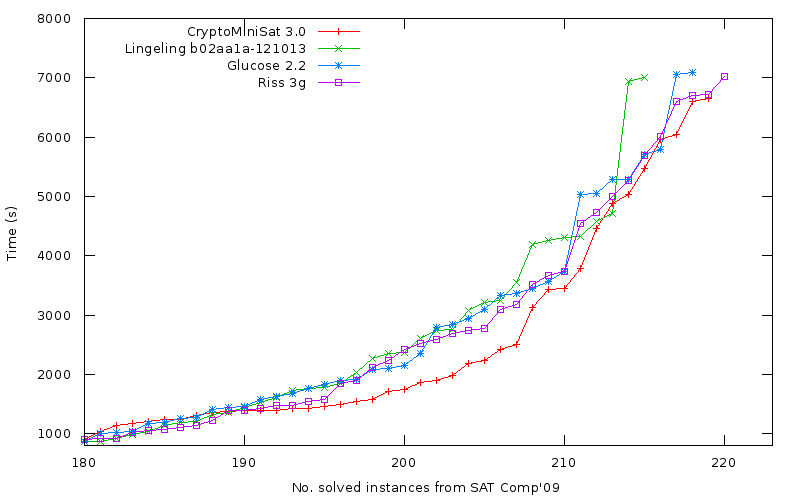
Riss 3g is winning this race, with CryptoMiniSat being second, third is glucose, and very intriguingly lingeling the 4th. Note that CryptoMiniSat leads the pack most of the time. Also note, this is the first time CryptoMiniSat 3.0 has been run for such a long time, while all the other competing solvers’ authors (lingeling, glucose, riss) have clusters available for research purposes.
Licensing
For those wondering if they could use this as a base for SAT Competition 2013, the good news is that the licence is LGPL so you can do whatever you want with it, provided you publish the changes you made to the code. However, I would prefer that you compete with a name such as “cms-MYNAME” unless you change at least 10% of the code, i.e. ~2000 lines. For the competitions after 2013, though, it’s all up for grabs. As for companies, it’s LGPL, so you can link it with your code, it’s safe, you only have to publish what you change in the library, you don’t have to publish your own code that uses the library.
Features
CryptoMiniSat has been almost completely rewritten from scratch. It features among other things:
- 4 different ways to propagate
- Implicit binary&tertiary clauses
- Cached implied literals
- Stamping
- Blocking of long clauses
- Extended XOR detection and top-level manipulation
- Gate detection and manipulation
- Subsumption, variable elimination, strengthening
- 4 different ways to clear clauses
- 4 different ways to restart
- Large amounts of statistics data, both into console and optionally to MySQL
- Web-based dynamic display of gathered statistics
- 3 different ways to calculate optimal variable elimination order
- On-the-fly variable elimination order update
- Super-fast binary&tertiary subsumption&strengthening thanks to implicit bin&tri
- On-the-fly hyper-binary resolution with precise time-control
- On-the-fly transitive reduction with precise time-control
- Randomised literal dominator braching
- Internal variable renumbering
- Vivification
- On-the-fly clause strengthening
- Cache&stamp-based learnt clause minimisation
- Dynamic strongly connected component check and equivalent literal replacement
Code layout
As for those wondering how large the code base is, it’s about 20KLOC of code, organised as: