This blog post is to promote the tool here (paper here) that converts weighted counting and sampling to their unweighted counterparts. It turns out that weighted counting and sampling is a thing. It’s basically a conjunctive normal form formula, a CNF, with weights attached to each variable. One must count the number of solutions to the CNF, where the weight of each solution is not necessarily 1, but weighted according to the polarity of each variable in the solution. One such formula could look like:
p cnf 2 1
c ind 1 2 0
1 2 0
w 1 0.9
This basically says that we have 2 variables, a single constraint (“v1 or v2”) where a solution with v1=True is worth 0.9 points, but a solution with v1=False is only worth 0.1 points. Or, if we are sampling, we want to bias our samples 9-to-1 for solutions that have v1=True.
Let’s go through this CNF. It has has 3 solutions, with its associated points:
The issue is that we have great tools for doing unweighted counting and sampling but few tools for doing weighted counting and sampling.
Converting Weighted CNFs to Unweighted CNFs
The solution is to use a converter to make an unweighted formula from a weighted formula, and then either divide the number of solutions of the unweighted formula (for counting) or simply cut off variables from the samples (for sampling). This work was done by Chakraborty et al. and presented at IJCAI’15. The basic idea is that we can approximate the weight with a binary representation and encode that in CNF. For example, 0.26 can be approximated with 1/4. If this weight is attached to v1, and there are 10 variables in the original CNF, we generate the extra set of clauses:
12 -1 0
11 -1 0
12 -11 1 0
This CNF has exactly 1 solution when v1=True and 3 solutions when v1=False. So the number of positive solutions is 1/4 of all solutions, i.e. 0.25, close to the requested 0.26.
The above set of clauses is generated from chain formulas that can be easily generated, and are only polynomal in size of the binary precision required. For k-bit precision (above: 2 bit precision), we need only k extra variables and k+1 clauses. See the paper for details, but it’s sufficient to say that it’s easy to generate and, looking through a few examples, quite easy to understand.
Example: Weighted Counting
Let’s do the full run, using our favorite counter, approxmc:
$ cat my.cnf
p cnf 2 1
c ind 1 2 0
1 2 0
w 1 0.9
$ ./weighted_to_unweighted.py my.cnf my-unweighted.cnf
Orig vars: 2 Added vars: 7
The resulting count you have to divide by: 2**7
$ ./approxmc my-unweighted.cnf
[…]
[appmc] FINISHED AppMC T: 0.01 s
[appmc] Number of solutions is: 62*2**2
$ python
>>> 62*2**2/2**7
1.9375
So, we got pretty close to the correct weighted count of 1.9. The reason for the discrepancy is because we approximated 0.9 with a 7-bit value, namely 115/2**7, i.e. 0.8984375, and we used an approximate counter. With an exact counter such as sharpSAT, we would have got:
And we are done! The sampling worked as expected: we get proportionally more samples where v1 is True than when it’s False.
Conclusions
Weighted counting is non-trivial but can be approximated using chain formulas, blowing up the original equation in only a minor way. This allows us to use well-optimized unweighted systems to perform the counting and sampling, and then trivially transform the output of these tools to match our original weighted problem.
This is going to be a long post, collecting many years of work, some of which was done by my colleagues Kuldeep Meel and Raghav Kulkarni. They have both significantly contributed to this work and I owe a lot to both. The research paper is available here (accepted to SAT’2019) and the code is available here. Build instructions are at the bottom of the post. Part 2 will deal with exploring the data in more detail.
I always had a fascination with data when it comes to SAT solving. My SAT solver, CryptoMiniSat always had very detailed stats printed to the console. At one point, this fascination with data got to the point where tallying up data from the console (with AWK, like a true hacker) didn’t cut it, and I started dumping data to SQL.
An Early Attempt: Visualization
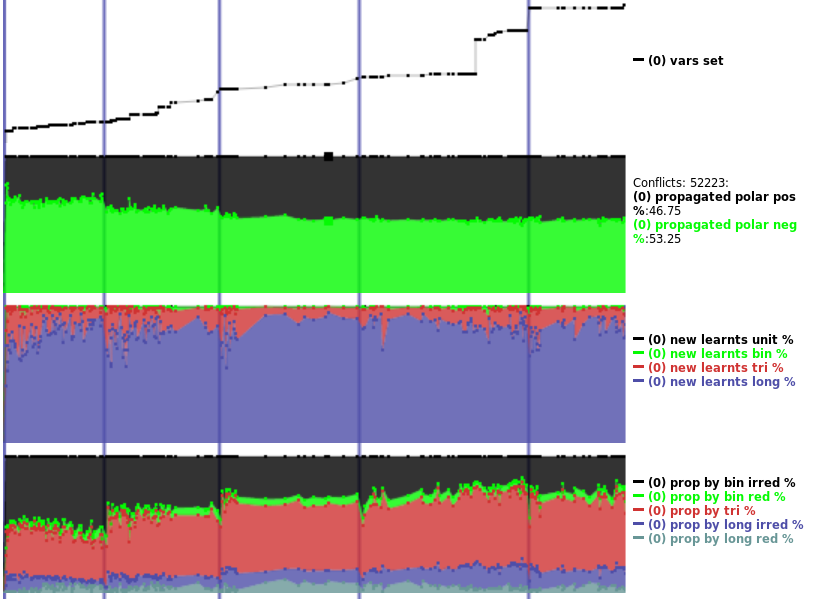
Out of the SQL data dumped, this website was born, back in 2012. This site displays pretty graphs like:
These graphs can show quite a bit of data, the above must be a few hundred data points. The data gathered is pumped to an SQL database, and then visualized. I felt like I am on to something. Finally, I was going to be able to explain things.
But I was able to explain very little. Some things were quite obvious, like how industrial and cryptographic instances’ variable polarity distributions were so different. Above, the black/green graph shows a cryptographic instance, and the distribution is 47% vs. 53%. On a typical industrial instance, the same graph looks like:
Here, the polarity distribution is 6% vs 94%. This is easy to see with the human eye. But I was gathering tons more data, many megabytes per instance. What was I going to do with all this data? How was I going to know what is good and bad behavior? And how would I make the solver work towards good?
SATZilla: Solver Selection Using Machine Learning
I wasn’t the only one trying to make sense of SAT-related data and improve solving based on it. SATZilla has done this before. There, the idea was to gather information — called features — about the input CNF problem, run multiple SAT solvers, save how much time it took for the solver to run, then create code that matches the CNF features to the preferred SAT solver. This creates a lines like:
Where the first N columns are the features and the last column is the label that we calculated to be correct. SATZilla uses many features, such as the number of horn clauses, the ratio of variables and clauses, etc. Once such a table has been built, with lines called labeled training examples, it uses a machine learning system, for example Decision Trees, to classify (i.e. guess) which SAT solver would be best for any CNF instance. So it generalizes, and can guess which SAT solver is best for a CNF it has never seen.
This system is interesting but has some drawbacks. First, for each data line one must run 5-10 SAT solvers on a CNF, potentially using up to 20-30’000 CPU seconds. Hence, each labeled training example is extremely expensive. If you know about the Big Data hype, you know that spending $2 on a single data point is not viable. Modern systems use millions of labeled training examples to learn a classifier. Secondly, this system was not designed to work in an industrial setting, where the CNF is not presented in a single file but piece-by-piece through a library interface.
Enter DRAT
DRAT is a system used to verify the resolution proof that modern SAT solvers generate. Basically, every unsatifiable problem that SAT solvers solve can be shown to be unsatisfiable through a set of operations called resolutions, that eventually lead to the equation 0=1, which is trivially false. A DRAT verifier can know exactly which clause was used by the SAT solver at exactly which time during the creation of the proof. Hence, DRAT knows a lot. It can actually tell, after the solving has finished, which parts of the SAT solving were absolutely useless, and which ones useful. A resolution proof with thousands of resolutions can be computed in seconds, which means cheap data.
When I first really understood DRAT, I realized, what if I could get all this data out of DRAT, and use it as a label for the millions of data points I already have? I have finally found a label, available at a huge scale, to train on.
The Beginnings of CrystalBall
What to train for was still a question that needed answering. Since DRAT is so intimately connected with learnt clauses, I decided to train for throwing away as many unneeded learnt clauses as possible. This would definitely make solving faster, by throwing away everything that is useless weight and making sure everything that is useful stays.
I must thank Marijn Heule who helped me with the first hack of DRAT-trim in early 2016 to get data out from from it. I hacked CryptoMiniSat to add Clause IDs to DRAT, so the verifier, DRAT-trim, could read and track these IDs. I now knew which clause was used in the proof and which wasn’t. This sounds really useful — you could now know which learnt clauses should have been thrown away the moment they were generated, since they were useless. Let’s see some data from modern CrystalBall (see at the bottom of the post how to download, compile and run):
sqlite> select count() from sum_cl_use where num_used>0;
51675
sqlite> select count() from sum_cl_use where num_used=0;
42832
The data says that about 50% of clauses were useful. Let’s see what is the average LBD value of the useful and useless clauses:
sqlite> select avg(glue) from sum_cl_use, clauseStats where sum_cl_use.clauseID = clauseStats.clauseID and num_used > 0;
6.71436865021771
sqlite> select avg(glue) from sum_cl_use, clauseStats where sum_cl_use.clauseID = clauseStats.clauseID and num_used = 0;
9.80162028389989
Nice. Let’s get the sizes, too, by replacing “glue” with “size”:
There are plenty more, well over a hundred, that is being measured, so I won’t bore you. I have a feeling you could write a few research papers just by running queries on this data.
I don’t know if you noticed, but something is odd here. SAT solvers only keep about 5-10% of all clauses. Just run a modern SAT solvers to completion and check how many clauses remain in the clause database. How is this compatible with 50% of clauses being useful? Well, we can use clauses for a while, then throw them away. But for that, we need much more than just whether a clause is useful or not. We need to know exactly when it was useful. Clauses can be used many-many times in a single proof.
We Need More Refined Labels
It turns out that having only whether a clause is being used is not good enough to compute useful labels. We need to know when, exactly, was the clause useful. So CryptoMiniSat and DRAT-trim was hacked to output into the DRAT proof exact conflict numbers when a clause was created. This, with some minor magic, would tell us exactly when each learnt clauses was used:
sqlite> select sum(num_used) from sum_cl_use, clauseStats where sum_cl_use.clauseID = clauseStats.clauseID and glue<=3;
332689
sqlite> select count() from clauseStats where glue<=3;
11221
For this problem, a clause that had LBD 3 or lower was used on average 332689/11221.0=29.65 times in the proof. Okay, how about clauses with LBD 4 or larger? It’s a trivial change in the above code, and gives us 5.95. Cool, the lower glue, the more it’s used in the proof.
Now that we know how to walk, let’s run. When was clauseID 59465 created and at what conflict points was it used in the proof?
sqlite> select conflicts from clauseStats where clauseID=59465;
101869
sqlite> select used_at from usedClauses where clauseID = 59465 order by used_at asc;
101870
123974
152375
This is an interesting clause. It was generated at conflict no. 101869, was used in the proof right after it was generated, at conflict no. 101870, and then it was used in the proof more than 20’000 conflicts later, twice.
The Data Pipeline
The idea is this: we are going examine every learnt clause at every 10’000 conflicts, and guess whether it’s going to be used in the future enough for it to be kept. If it’s going to be used enough in the future, we keep it. If not, we’ll throw it away. What do we need for this?
Well, we need a ton of labeled training examples. And for that, we need a truckload of data, one that generates so much that we have to throw away 96% and still end up with hundreds of MBs in under an hour. Also, we need this from a wide variety of problems, and we need to be able to debug the hell out of this data, because where there is tons of data, there are tons of NaNs, and negative clause sizes and the whatnot. So we need a data pipeline.
The first part of the pipeline we only run once, because it’s a bit expensive, about 3-10x slower than a normal CNF run, and looks like this:
Run CryptoMiniSat without any clause cleaning, and write an SQLite database with all dynamic data gathered. The data written is about: the CNF (such as number of claues, etc.), the restarts (e.g. avg. LBD, restart length), the learnt clauses (e.g. LBD, size), and at every 10’000 conflicts the dynamic characteristics of the learnt clauses (e.g. activity, number of times used in a conflict the past 10’000 conflicts)
Run DRAT, and dump all usage data to a file. Augment the SQLite data with the DRAT data
Sample the data because otherwise it’s going to be too much. We need to sample smartly, though, because without biased sampling, the really weird cases will not be represented in the final data at all, and our machine learning system will not see some really interesting data. If we could store and process 1TB of data (you can generate that rather easily), we wouldn’t have this issue. But we can’t.
So now we have a ton of cool data that is very raw. This is going to be our baseline. We’ll keep this data in our stash and never modify it.
The second part of our data pipeline will use this stash of data to do all the cool things we want. This 2nd part is much-much cheaper to run (few seconds to a few minutes per CNF), so we will be able to run it as many times as we like, playing with all the cool parameters. This second part of the pipeline will:
The data is stored normalized in SQLite for speed and space. For machine learning, we must denormalize it, to have everything related to decision on a single line.
Create the labeled training data using Python Pandas for easy data manipulation and visualization
Notice that this table has essentially two parts. The left part, i.e. everything apart from “keep”, called features, must be available to the solver during running. And the right part, “keep”, the label, which is computed using data from DRAT-trim. This latter the solver has no access to during running, this is our crystal ball, looking into the future. What we want is to predict the label given the features.
The left hand side, i.e. the features are not so difficult to do. Adding a new feature is now about 3-4 lines change in CryptoMiniSat and it’s essentially free in terms of speed. The data gathering only needs to run once (the 1st part of our data pipeline) and it is not running during solving. So, you can add as many features as you like. If they are useful, then you also need to add some lines to the solver so they will be available during running — of the 200+ only a few are really useful.
The right hand side, i.e. the labels are a completely different story, though. We know what is the future, kinda (yes, the future is a function of the past&present, but let’s not go there for the moment). So given the future, how do I label things? We need to use a heuristic. The good part is that we have a ton of information about the future, such as the distribution of all clause’s usage in the proof, and the number of times a particular clause is used in the future. But we still need to come up with something to decide KEEP/THROW_AWAY. A simple such heuristic is: if in the next 10’000 conflicts this clause will be used at least 6 times, keep it. Otherwise, into the bin it goes:
CASE WHEN
-- useful in the next round
used_later10k.used_later10k > 5
THEN "keep" ELSE "throw_away"
END AS `x.class`
Nice! Remember that clauseID 59465 that I talked about above? Yeah, that would be labeled THROW_AWAY — it was only used 20’000 conflicts later. We have labeled our data, now we need to train a classifier, make it output C++ code and we are good to go. But before that, let’s play with Weka.
Data Analysis And Machine Learning with Weka
Weka is a cool tool for exploring data and building simple classifiers. You can get a free Weka course on Futurelearn, and I highly recommend it. The person who wrote it is the one who is giving the course and he is really cool. The denormalized, labeled data can be output to CSV (see at the bottom), which Weka can read:
Here, you have Weka showing the denormalized set of features on the left, and showing the LBD distribution on the right. Blue color is for for lines labeled KEEP and red color is for lines labeled THROW_AWAY. As you can see, the distribution of blue vs red is not the same at all as the LBD value increases (hence LBD being a good discriminator, see glucose).
You can also visualize correlations:
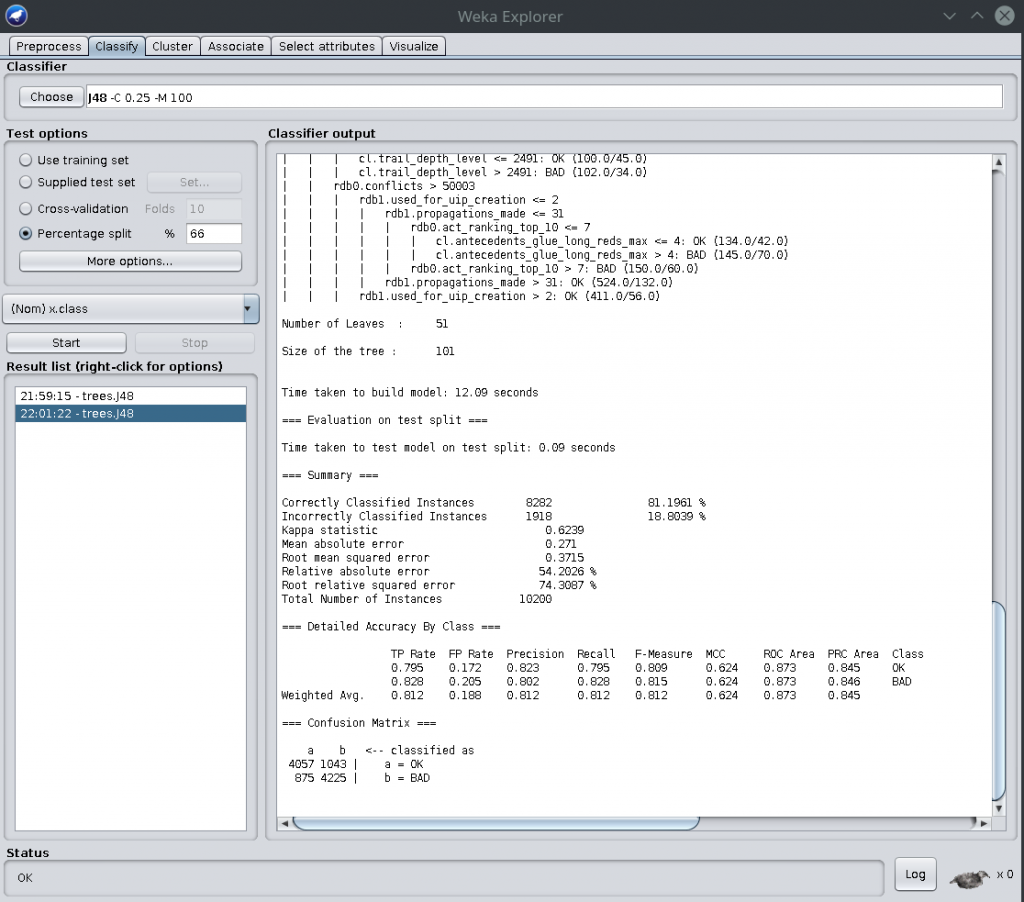
You can also build classifiers based on this labeled data. Just don’t forget to delete the “sum_cl_use.*” features, as they are not really features, they are data from the proof verification. If you don’t delete them, Weka will cheat and use them in the classifier, which is like using the solution key during the exam :) Let’s create a classifier using Weka:
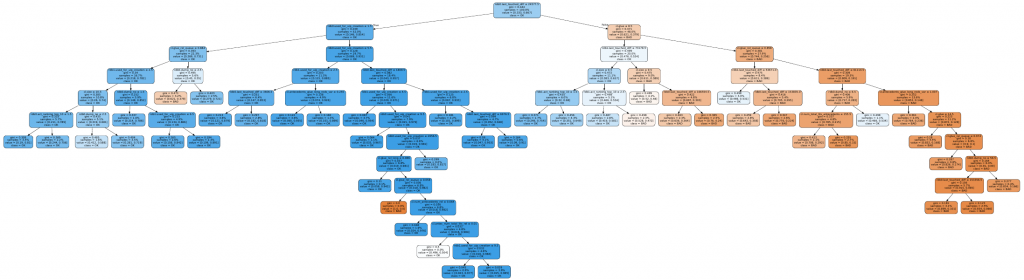
This shows a confusion matrix at the bottom. Nice. Total misclassification was 18% using the J48 decision tree algorithm with some minor tuning. Here is such an example decision tree (PDF here):
Weka is great in many ways, and I will forever be indebted to it. However, it’s just not gonna cut it for us. We need something a lot faster, and we need to be able to automate it and we need to be able to get C++ code out. Weka could do some of these, but I’m not a Java programmer, and Weka’s speed is nowhere near that of scikit-learn. However, if it’s your first time doing machine learning, Weka is an amazing tool.
Training a Classifier Using scikit-learn
Now that we have labeled training data, we need to create a classifier so that the solver, during running, can take the features it knows and guess the label KEEP or THROW_AWAY. There are many-many different classifiers that can be trained, and I have tried the most important ones, such as logistic regression,SVM, decision trees and random forests.
Let me pause here for a moment. If you haven’t done machine learning before, you might think — this is where the magic is. The classifier is where it’s at! And if you have done machine learning before, you know full well, it’s not here at all. It turns out that the quality and quantity of your data is way more important than the classifier you choose. It’s relatively easy to see why. If your data is messy, incorrect, or missing elements, no matter what classifier you use, no matter how amazing it is, it will give you bad results. Bad data, bad results. Every. Single. Time. Keep this in mind.
So, we have chosen our classifier, say, decision trees. Decision trees are easy to visualize, and you will need to debug the hell out of this, so it comes handy. After all, nobody wrote 1000 lines of python and it came out perfect the first time.
Now, there are still some things to deal with. First, we cannot possibly use all 200+ features in our prediction. We can generate the tables, but we need to be reasonable, and cut down the features to something much smaller, say, 20, during the running of the solver. To do that, we create a large random forest and then check which features were picked by the most trees. That gives us feature ranking (thanks to Raghav Kulkarni for this trick):
So the top 5 features for this particular run are these. For different instances or different configurations, the top features may differ, and you probably want to sample X number of labeled training example from each problem, put it in a large data file and then run the feature ranking.
There are still some minor obstacles to overcome. Since about 95% of the clauses need to be thrown away, our labels will be very unbalanced. So we need to balance that. Also, how aggressive do we want to be with throwing clauses away? Should we err on the side of caution? Note that this is not about labeling anymore. The label has already been chosen. It’s about guessing the label. We are now tuning what’s called the confusion matrix:
Here, we have 80% of things that we labeled as KEEP actually being guessed to be kept, while 20% of them are wrongly guessed as THROW_AWAY. So it’s kinda okay. We are better at guessing if something needs to be thrown away, though, there we only guess 5% of them wrongly. Maybe this a good balance, but if not, it can be changed as a weight parameter.
The system can also classify clauses into different types, using K-means clustering. Then it can train a different classifier for each clause type. The K-means clustering uses the already denormalized features, so it’s really trivial to do, though which features should be used for the clustering is a good question. I currently use the CNF features only (e.g. number of clauses, variables, ratio of vars/clauses, etc.), thereby clustering problems rather than clauses. One could could use any set of features though, it’s all automatic, including C++ code generation.
Actually, the C++ code generation. The system produces C++ code for decision trees, random forests and K-means clustering, ready for it to be compiled into the final executable. We have now created our clustering and classifier, and it’s all in C++ code. Let’s run it!
The Final Solver
This is the most fun part. And the cumulative effort of a lot of work. It’s really interesting to see all those thousands of lines of C++ and python churning out gigabytes of data, being boiled down to juts a few hundred lines of automatically generated if-then-else statements, running during solving. But there it is.
Let me talk about the good parts first. It’s very fast at evaluating whether to keep or throw away a clause. You don’t even notice it running. It doesn’t use much more memory than normal CryptoMiniSat (i.e. a few features were enough), and it correctly guesses the cluster where a clause belongs. It also guesses the labels correctly with very high probability. The final solver beats every solver from 2018 on the SAT competition 2014-17 instances.
Another great thing is that this system can be used to automatically train forspecific problem types. This can be very significant in industry, where the instances are similar and training for a particular type of instance would make a lot of sense. Since this system tunes to the data it’s given, if it’s given data only about a particular type of instances, it will tune to them only, making the solver particularly good at them.
There is a bad part too, though: the built-in, rather sophisticated heuristic of keeping or throwing away clauses beats the system built. This makes me very sad, but some things make me hopeful. Firstly, the data is probably still messy. There are probably some bugs here and there, where some of the data gathered is not reliable. Secondly, the labeling is very-very rudimentary. If you have a look at that CASE statement above, it’s laughingly simple. Finally, the normal heuristic is quite smart, keeping some (simple) information about clauses, i.e. keeping some state over time, which the current machine learning system cannot do — the classifier has no memory.
Conclusions
This project, going back over 6 years, has been a tough one. All in all, it must have costed about 2 full years of work. A sane researcher would have abandoned it after about 2 weeks. In fact, we had a reviewer rejecting the paper, claiming that this work could be done in 2 weeks by her/his PhD student (I love such reviews). I sometimes wonder how much that PhD student charges for their time, because I might just pay it if they are that good.
Maybe we did the wrong thing, keeping going for so many years, but I think this could be a foundation of something much more interesting. It could be used not only to create machine learning models, but also to understand SAT solvers. With so much data at hand, we could finally understand some of the behavior of solvers, perhaps leading to some interesting ideas. And the data could be used for many other machine learning systems, too: guessing when to restart, guessing which variable to branch on, etc.
Build and Use Instructions
# Prerequisites on a modern Debian/Ubuntu installation
sudo apt-get install build-essential cmake git
sudo apt-get install zlib1g-dev libsqlite3-dev
sudo apt-get install libboost-program-options-dev
sudo apt-get install python3-pip
sudo pip3 install sklearn pandas numpy lit matplotlib
# Getting the code
git clone https://github.com/msoos/cryptominisat
cd cryptominisat
git checkout crystalball
git submodule update --init
mkdir build && cd build
ln -s ../scripts/crystal/* .
ln -s ../scripts/build_scripts/* .
# Let's get an unsatisfiable CNF
wget https://www.msoos.org/largefiles/goldb-heqc-i10mul.cnf.gz
gunzip goldb-heqc-i10mul.cnf.gz
# Gather the data, denormalize, label, output CSV,
# create the classifier, generate C++,
# and build the final SAT solver
./ballofcrystal.sh --csv goldb-heqc-i10mul.cnf
[...compilations and the full data pipeline...]
# Let's use our newly built tool
# we are using configuration number short:3 long:3
./cryptominisat5 --predshort 3 --predlong 3 goldb-heqc-i10mul.cnf
[ ... ]
s UNSATISFIABLE
# Let's look at the data
cd goldb-heqc-i10mul.cnf-dir
sqlite3 mydata.db
sqlite> select count() from sum_cl_use;
94507
Satisfiability problem solvers, or SAT solvers for short, try to find a solution to decidable, finite problems such as cryptography, planning, scheduling, and the like. They are very finely tuned engines that can be looked at in two main ways . One is to see them as proof generators, where the SAT solver is building a proof of unsatisfiability as it runs, i.e. it tries to prove that there is no solution to the problem. Another way is to see SAT solvers as smart search engines. In this blog post, I’ll take this latter view and try to explain why I think intermediary variables are important. So, for the sake of argument, let’s forget that SAT solvers sometimes restart the search (forgetting where they were before) and learn clauses (cutting down the search space and remembering where not go again). Let’s just pretend all they do is search.
Searching
The CryptoMiniSat SAT solver used to be able to generate graphs that show how a search through the search space went. Search spaces in these domains are exponential in size, say, 2^n in case there are n variables involved. I don’t have the search visualization code anymore but below is an example of such a search tree. The search starts at the very top not far from the middle, it descends towards the bottom left, then iteratively backtracks all the way to the top, and then descends towards the bottom right. Every pentagon at the bottom of a line is a place where the SAT solver backtracked. Observe that it never goes all the way back to the top — except once, when the top assignment needs to be flipped. Instead, it only goes back some way, partially unassigning variables. The bottom right corner is where the solution is found after many-many partial backtracks and associated partial unassignements:
What I want you to take away from this graph is the following: the solver iteratively tries to set a variable a value, calculates forward, and if it doesn’t work, it will partially backtrack, flip its value to its opposite, then descend again.
Brute force search vs. SAT solving
Trying one value and then trying the other sounds suspiciously like brute force search. Brute force search does exactly that, in a systematic and incredibly efficient way. We can build highly specialized executables and even hardware, to perform this task. If you look at e.g. Bitcoin mining, you will see a lot of specialized hardware, ASICs, doing brute-force search. And if you look at rainbow tables, you’ll see a lot of bit slicing.
So why waste our time doing all this fancy value propagation and backtracking when we could use a much more effective, systematic search system? The answer is, if you generated your problem description wrongly, then basically, for no good reason, and you are probably better off doing brute-force search. But if you did well, then a SAT solver can perform a significantly better search than brute-force. The trick lies in intermediary variables, and partial value assignments.
Partial value assignments
So let’s say that your brute force engine is about to check one input variable setting. It sets the input variables, runs the whole algorithm, and computes the output. The output is wrong though. Here is where things go weird. The brute force engine now completely erases its state, takes another input and runs the whole algorithm again.
So, brute force does the whole calculation again, starting from a clean state, every time. What we have to recognize is that this is actually a design choice. Another design choice is to calculate what variables were affected by one of the input bits, unset these variables, flip the input bit value, and continue running the calculation. This has the following requirements:
A way to quickly determine which intermediate values depend on which other ones so we can unset variables and know which intermediate, already calculated, dependent variables also need to be unset.
A way to quickly unset variables
A good set of intermediary values so we can keep as much state of the calculation as possible
If you think about it, the above is what SAT solvers do, well mostly. In fact, they do (1) only partially: they allow variables only to be unset in reverse chronological order. Calculating and maintaining a complete dependency graph seems too expensive. So we unset more variables than we need to. But we can unset them quickly and correctly and we compensate for the lack of correct dependency check in (1) by caching polarities. This caches the independent-but-nevertheless-unset variables’ values and then hopes to reassign them later to the correct value. Not perfect, but not too shabby either.
Modeling and intermediary variables
To satisfy requirement (3) one must have a good set of intermediary variables in the input problem (described in DIMACS format), so the SAT solver can both backtrack and evaluate partially. Unfortunately, this is not really in the hands of the SAT solver. It is in the hands of the person describing the problem. Modeling is the art of transforming a problem that is usually expressed in natural language (such as “A person cannot be scheduled to be on a night shift twice in a row”) into a problem that can be given to a SAT solver.
Modeling has lots of interesting constraints, one of which I often hear and I am confused by: that it should minimize the number of variables. Given the above, that SAT solvers can be seen at as partial evaluation engines that thrive on the fact that they can partially evaluate and partially backtrack, why would anyone try to minimize the number of variables? If the solver has no intermediary variables to backtrack to, the solver will simply backtrack all the way to the beginning every time, thus becoming a really bad brute-force engine that incidentally tracks a dependency graph and is definitely non-optimized for the task at hand.
Some final thoughts
In the above I tried to take a premise, i.e. that SAT solvers are just search engines, and ran with it. I don’t think the results are that surprising. Of course, nothing is black-and-white. Having hundreds of millions of variables in your input is not exactly optimal. But minimizing the number of variables given to a SAT solver at the expense of expressive intermediate variables is a huge no-no.
I am happy to finally release a piece of work that I have started many years ago at Security Research Labs (many thanks to Karsten Nohl there). Back in the days, it helped us to break multiple real-world ciphers. The released system is called Bosphorus and has been released with major, game-changing work by Davin Choo and Kian Ming A. Chai from DSO National Laboratories Singapore and great help by Kuldeep Meel from NUS. The paper will be published at the DATE 2019 conference.
ANFs and CNFs
Algebraic Normal Form is a form that is used by most cryptographers to describe symmetric ciphers, hash algorithms, and lately a lot of post-quantum asymmetric ciphers. It’s a very simple notation that basically looks like this:
x1 ⊕ x2 ⊕ x3 = 0 x1 * x2 ⊕ x2 * x3 + 1 = 0
Where “⊕” represents XOR and “*” represents the AND operator. So the first line here is an XOR of binary variables x1, x2 and x3 and their XOR must be equal to 0. The second line means that “(x1 AND x2) XOR (x2 AND x3)” must be equal to 1. This normal form allows to see a bunch of interesting things. For example, it allows us to see the so-called “maximum degree” of the set of equations, where the degree is the maximum number of variables AND-ed together in one line. The above set of equations has a maximum degree of 2, as (x1*x2) is of degree 2. Degrees can often be a good indicator for the complexity of a problem.
What’s good about ANFs is that there are a number of well-known algorithms to break problems described in them. For example, one can do (re)linearization and Gauss-Jordan elimination, or one could run Grobner-basis algorithms such as F4/F5 on it. Sometimes, the ANFs can also be solved by converting them to another normal form, Conjunctive Normal Form (CNF), used by SAT solvers. The CNF normal form looks like:
x1 V x2 V x3 -x1 V x3
Where x1, x2 and x3 are binary variables, “V” is the logical OR, and each line must be equal to TRUE. Using CNF is interesting, because the solvers used to solve them, SAT solvers, typically provide a different set of trade-offs for solving than ANF problem solvers. SAT solvers tend to use more CPU time but a lot less memory, sometimes making problems viable to solve in the “real world”. Whereas sometimes breaking of a cipher is enough to be demonstrated on paper, it also happens that one wants to break a cipher in the real world.
Bridging and Simplifying
Bosphorus is I believe a first of its kind system that allows ANFs to be simplified using both CNF- and ANF-based systems. It can also convert between the two normal forms and can act both as an ANF and a CNF preprocessor, like SatELite (by Een and Biere) was for CNF. I believe this makes Bosphorus unique and also uniquely useful, especially if you are working on ANFs.
Bosphorus uses an iterative architecture that performs the following set of steps, either until it runs out of time or until fixedpoint:
Replace variables and propagate constants in the ANF
Run limited ElimLin and inject back unit and binary XORs
Convert to CNF, run a SAT solver for a limited number of conflicts and inject back unit and binary (and potentially longer) XORs
In other words, the system is an iterative simplifier/preprocessor that invokes multiple reasoning systems to try to simplify the problem as much as possible. It can outright solve the system, as most of these reasoning systems are complete, but the point is to run them only to a certain limit and inject back into the ANF the easily “digestible” information. The simplified ANF can then either be output as an ANF or a CNF.
Bosphorus can also take a CNF as input, perform the trivial transformation of it to ANF and then treat it as an ANF. This allows the CNF to be simplified using techniques previously unavailable to CNF systems, such as XL.
ANF to CNF Conversion
I personally think that ANF-to-CNF conversion is actually not that hard, and that’s why there hasn’t been too much academic effort devoted to it. However, it’s an important step without which a lot of opportunities would be missed.
The implemented system contains a pretty advanced ANF-to-CNF converter, using Karnaugh tables through Espresso, XOR cutting, monomial reuse, etc. It should give you a pretty optimal CNF for all ANFs. So you can use Bosphorus also just as an ANF-to-CNF converter, though it’s so much more.
Final Thoughts
What I find coolest about Bosphorus is that it can simplify/preprocess ANF systems so more heavyweight ANF solvers can have a go at them. Its ANF simplification is so powerful, it can even help to solve some CNFs by lifting them to ANF, running the ANF simplifiers, converting it back to CNF, and solving that(!). I believe our initial results, published in the paper, are very encouraging. Further, the system is in a ready-to-use state: there is a Docker image, the source should build without a hitch, and there is even a precompiled Linux binary. Good luck using it, and let me know how it went!
Approximate model counting allows to count the number of solutions (or “models”) to propositional satisfiability problems. This problem seems trivial at first given a propositional solver that can find a single solution: find one solution, ban it, ask for another one, ban it, etc. until all solutions are counted. The issue is that sometimes, the number of solutions is 2^50 and so counting this way is too slow. There are about 2^266 atoms in the universe, so counting anywhere near that is impossible using this method.
Exact Counting
Since we cannot count 1-by-1, we are then left with trying to count in some smarter way. There are a bunch of methods to count exactly, the simplest is to cut the problem on a variable, count when the variable is True, count when the variable is False, recursively, and add them all up. Given caching of components that recur while “cutting” away, this can be quite successful, as implemented by sharpSAT (see Marc Thurley’s paper).
These counters can scale quite well, but have some downsides. In particular, when the memory runs out, the cache needs to be groomed, sometimes resorting back to 1-by-1 counting, which we know will fail as there is no way 2^200 can be counted 1-by-1 in any reasonable amount of time. The caching systems used are smart, though, retaining last-used entries when the cache needs to be groomed. However, sometimes this grooming algorithm can lead to cyclic behaviour that effectively simulates 1-by-1 counting.
Approximate Counting
What Chakraborty, Meel and Vardi did in their paper, was to create a counter that counts not exactly, but “probably approximately correctly”. This jumble of terms basically means: there is a certain probability that the counting is correct, within a given threshold. We can both improve the probability and the threshold given more CPU time spent. In practical terms, the probability can be set to be over 99.99% and the threshold can be set to be under 20%, still beating exact counters. Note that 20% is not so much, as e.g. 2^60*1.2 = 2^(60.3).
A Galton Box
So what’s the trick? How can we approximately count and give guarantees about the count? The trick is in fact quite simple. Let’s say you have to count balls, and there are thousands of them. One way to do it is to count 1-by-1. But, if you have a machine that can approximately half the number of balls you have, it can be done a lot faster: you half the balls, then check if you have at least 5 doing 1-by-1 counting. If you do, you half them again, and check if you have at least 5, etc. Eventually, let’s say you halved it 11 times and now you are left with 3 balls. So approximately, you must have had 3*2^11 = 6144 balls to begin with. In the end you had to execute the 1-by-1 count only 11*5+3+1 =59 times — a lot less than 6144! This is the idea used by ApproxMC.
Approximately Halving Using XORs
The “approximate halving” function used by ApproxMC is the plain XOR function, populated with variables picked with 50% probability. So for example if we have variables v1…v10, we pick each variable with 50% probability and add them into the same XOR. Let’s say we picked v1,v2,v5 and v8. The XOR would then be: v1⊕v2⊕v5⊕v8=1. This XOR is satisfied if an odd number of variables from the set {v1,v2,v5,v8} are 1. This intuitively forbids about half the solutions. The “intuitively” part of course is not enough, and if you read the original paper you will find the rigorous mathematical proof for the approximate halving of solutions this XOR function provides.
OK, so all we need to do is add these XORs to our original problem and we are done! This sounds easy, but there is a small hurdle and there is a big hurdle associated with this.
The small hurdle is that the original problem is a CNF, i.e. a conjunction of disjunctions, looking like “(v1 OR v2) AND (v2 OR not v3 OR not v4) AND…”. The XOR obviously does not look like this. The straightforward translation of XOR into CNF is exponential, so we need to add some variables to cut them smaller. It’s not that hard to figure this out and eventually add all the XORs into the CNF.
XORs, CDCL, and Gauss-Jordan Elimination
The larger hurdle is that once the XORs are in the CNF using the translation, the CNF becomes exponentially hard to solve using standard CDCL as used in most SAT solvers. This is because Gauss-Jordan elimination is exponentially hard for the standard CDCL to perform — but we need Gauss-Jordan elimination because the XORs will interact with each other, as we expect there to be many of them. Without being able to resolve the XORs with each other efficiently and derive information from them, it will be practically impossible to solve the CNF.
The solution is to tightly integrate Gauss-Jordan elimination into the solving process. CryptoMiniSat was the first solver to do this tight integration (albeit only for Gaussian elimination, which is sufficient). Other solvers have followed, in particular the work by Tero Laitinen and work by Cheng-Shen Han and Jie-Hong Roland Jiang. CryptoMiniSat currently uses the code by Han and Jiang after some cleanup and updates.
The latest work on ApproxMC and CryptoMiniSat has added one more thing besides the tight integration of the CDCL cycle: it now allows in- and pre-processing to occur while the XORs are inside the system. This brought some serious speedups as pre- and inprocessing are important factors in SAT solving. In fact, all modern SAT solvers strongly depend on them being active and working.
Concluding Remarks
We have gone from what model counting is, through how approximate counting works from a high-level perspective, all the way to the detail of running such a system inside a modern SAT solver. In case you want to try it out, you can do it by downloading the pre-built binaries or building it from source.