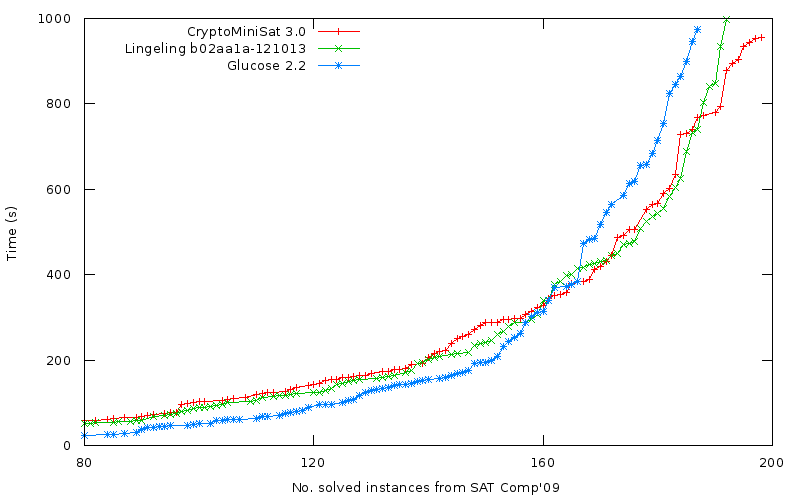
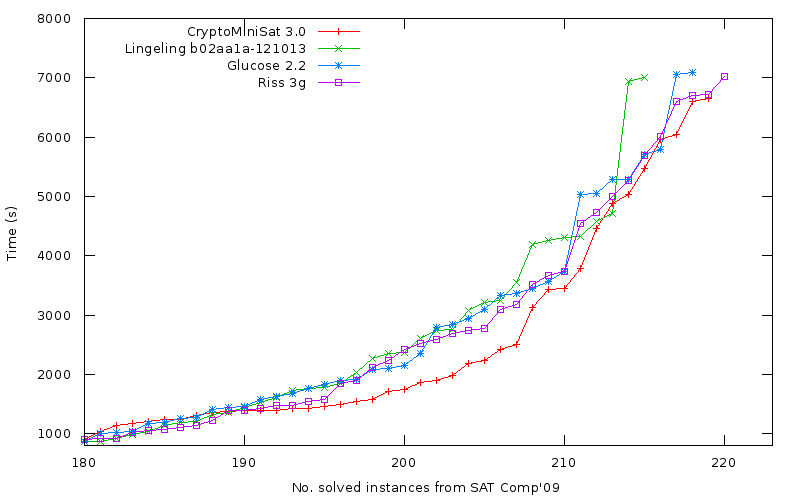
As many of you have heard, the SAT Competition for this year has been announced. You can send in your benchmarks between the 12th and the 22nd of April, so get started. I have a bunch of benchmarks I have already submitted about 2 years ago, still waiting for any reply from those organizers — but the organizers are different this year, so fingers crossed.
What I want to talk about today is benchmark randomization. This is a very-very touchy topic. However, I fear that it’s touchy for the wrong reasons, and so I think it’s important to talk about it in detail.
What is benchmark randomization?
Benchmark randomization is when a benchmark that is submitted is shuffled around a bit. There are many ways to shuffle a problem, and I will discuss this in a bit, but the point is that the problem at hand that is described by the benchmark CNF should not be changed, or changed only in a very-very minor way, such that everyone agrees that it doesn’t affect the core problem itself as described by the CNF.
Why do we need shuffling?
We need shuffling because simply put, there aren’t enough good benchmarks and so the benchmarks of yesteryear (and the year before, and before, and…) re-appear often. This would be OK if SAT solvers couldn’t be tuned to solving specific problems faster. Note that I am not suggesting that SAT solvers are intentionally manipulated to solve specific problems faster by unscrupulous researchers. Instead, the following happens.
Unintentional random seed improvements
Researchers test the performance of their SAT solvers on specific instances and then tune their solvers, testing the performance again and again on the same instances to check if they have improved performance. Logically this is the best way to test and improve performance: use the same well-defined test-set all the time for meaningful comparison. Since the researcher wants to use the instances that he/she thinks is the current use-case of SAT solvers, he naturally uses the instances of SAT competitions, since those are representative. I did and still do the same.
So, researchers add their idea to a SAT solver, and test. If the idea is not improving things then some change is made and tested again. Since modern CDCL SAT solvers behave quite randomly, and since any change in the source code changes the behaviour quite significantly, a small change in the source code (tuning of a parameter, for example) will change the behaviour. And since the set of problems tested on is fixed, there is a chance that more problems will be solved. If more are solved, the researcher might correctly interpret this as a general improvement, not specific to the problem set. However, it may very well be generic, it is also specific.
The above suggests that the randomness of the SAT solver is completely unintentionally tuned to specific problems — a subset of which will appear next year in the competition.
Easy fixes
Since there aren’t enough benchmark problems, and in particular some benchmark types are rare, I suggest to fix the unintentional tuning of solvers to specific problems by changing the benchmarks in minor ways. Here is a list, with an explanation why I think it’s OK to perform the manipulation:
- Propagate variables. Unitary clauses are often part of benchmarks. Propagating some of these, some recursively, gives quite a bit of problem space variation. Propagation is performed by every CDCL SAT solver, and I think many would be surprised if it didn’t help SAT solvers that worked differently than current SAT solvers. Agreeing on performing partial propagation is something that shouldn’t be too difficult.
- Renumber variables. For some variable X that is not used (or is fixed to a value that has been propagated), every variable that is higher than X is decremented by one, and the CNF header is fixed to reflect this change. Such a minor renumbering may be approved by every researcher as something that doesn’t change the problem or its structure. Note that if partial propagation is performed there should be quite a number of variables that can be removed. Renumbering some, but not others is a way to shuffle the problem. A more radical way of renumbering variables would be to completely shuffle them, however that would change the way the problem is described in quite a radical way, so some would correctly object and it’s not necessary anyway.
- Replace equivalent literals. Perform strongly connected component analysis and replace equivalent literals. This has been shown to significantly improve performance and I have never seen a case where it doesn’t. Since equivalent literal replacement can be performed with a lot of freedom, this is quite a bit of shuffling space. For example, if v1=v2=v3, then any of the v1, v2, v3 can be the one that replaces the rest in the CNF. Picking one randomly is a way to shuffle the instance
There are other ways of shuffling, but either they change the instance too much (e.g. blocked clause removal), or can be undone quite easily (e.g. shuffling the order of the clauses). In fact, (3) is already quite a touchy issue I think, but with (1) and (2) all could agree on. Neither requires the order of the literals or the order of the clauses to change — some clauses (e.g. unitary ones) and literals (some of those that are set) would be removed, but that’s all. The problem remains essentially unchanged such that most probably even the original problem author would easily recognize it. However, it would be different from a SAT solver point of view: these changes would change the random seed of the solver, forcing the solver to behave in a way that is less tuned to this specific problem instance.
Conclusion
SAT solvers are currently tuned too much to specific instances. This is not intentional by the researchers, however it still affects the results. To obtain better, less biased results we should shuffle the problem instances we have. Above, I suggested three ways to shuffle the instances in such a way that most would agree they don’t disturb or change the complexity of the underlying problem described by the instance. I hope that some of these suggestions will be employed, if not this year then for next year’s SAT competition such that we could reach better, more meaningful results.